As non-native speakers learn a new language, encountering words outside one’s vocabulary can impact their reading fluency. Automatically detecting these unknown words can help drive interactive methods to support reading. Previous methods of unknown word detection methods rely on gaze features obtained through eye trackers, with their detection accuracy greatly affected by the accuracy of eye tracking devices. In this work, we present a real-time and high-accuracy unknown word detection method by combining information about the text with gaze data. We utilize pre-trained language models and knowledge grounding to analyze text for unknown word probabilities. We then combine this text data with gaze information through a transformer-based model. The accuracy of our unknown word detection method is 97.6\%, and the F1-score is 71.1\%. The latency is within 1 second. To demonstrate the robustness of our method, we applied our method to another dataset collected with a relatively inaccurate webcam-based eye-tracking system. Our model can achieve the accuracy of 97.3\% and the F1-score of 65.1\% opening the potential for more accessible solutions than previously possible. Finally, we explore the applications space that can be enabled by our method.
Motivation
- Automatically detecting these unknown words can help drive interactive methods to support reading.
- Eye-tracking devices are expensive and prone to inaccuracies.

Contributions
- We propose a real-time gaze-based unknown word detection method that integrates the text information processed by the pre-trained language model. It can achieve the accuracy of 97.6% and the F1-score of 71.1%. The latency is within 1 second.
- We demonstrate that our method has the potential to be easily accessed in everyday life through a webcam-based unknown word detection system. The accuracy of our model on the gaze data obtained by webcam is 97.3% and the F1-score is 65.1%.
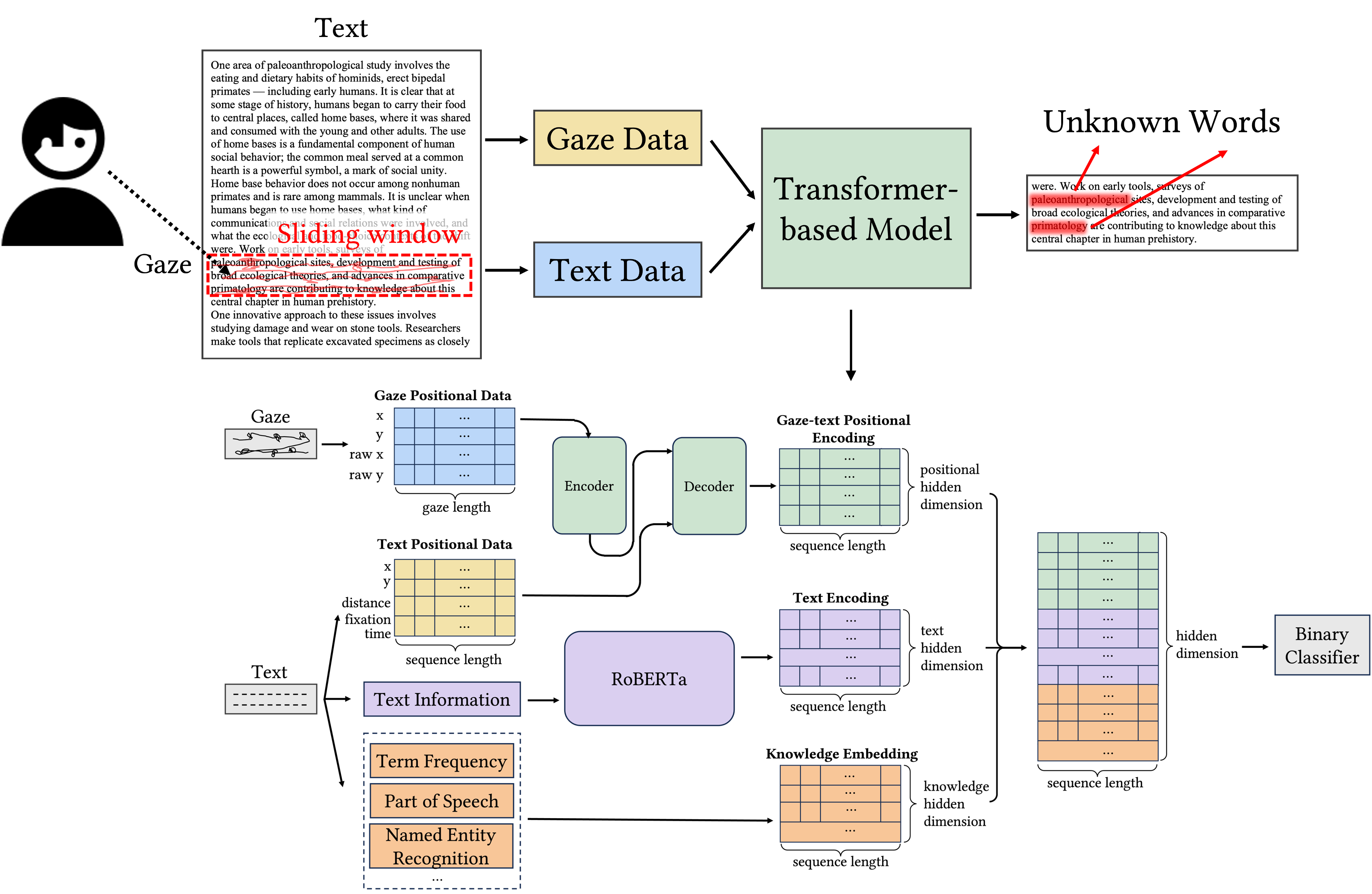
Method
- An encoder-decoder model to encode positional data: The encoder learns to capture the user’s gaze pattern, and the decoder is expected to predict whether a token belongs to an unknown word of the user.
- A pre-trained RoBERTa to encode text information: For token-level textual information encoding, we use pre-trained RoBERTa which has the advantage of encoding the token using the surrounding text to establish the context.
- Learnable embeddings to encode the knowledge: To further utilize the word-level information, we introduced knowledge including the term frequency, part of speech, and named entity recognition.
Results
Main Result
- The accuracy is 97.6% and the F1-score is 71.1%, which is higher than the state-of-arts.
- The accuracy on less precise webcam-based gaze data is 97.3%, showing the robustness of our method.
| Device | Method | Accuracy | F1-score | Precision | Recall |
|---|
| Eye tracker | Distance Heuristics | 76.6 | 20.6 | 13.3 | 45.5 |
| Eye tracker | Fixation Heuristics | 82.4 | 22.9 | 16.2 | 39.1 |
| Eye tracker | Logistic Regression | 96.6 | 23.4 | 15.9 | 44.5 |
| Webcam | Distance Heuristics | 74.1 | 19.7 | 12.1 | 54.0 |
| Webcam | Fixation Heuristics | 78.6 | 21.6 | 13.8 | 50.0 |
| Webcam | Logistic Regression | 96.7 | 20.3 | 13.0 | 45.6 |
| Eye tracker | Our Method | 97.6 | 71.1 | 63.3 | 79.0 |
| Webcam | Our Method | 97.3 | 65.1 | 60.3 | 69.7 |
Ablation Study
- It is efficient to use PLMs for better capturing the contextual information of the documents.
- Gaze patterns help identify whether a difficult word is an unknown word.
| Model | Accuracy | F1-score | Precision | Recall |
|---|
| Our method | 97.6 | 71.1 | 63.3 | 79.0 |
| w/o textual encoding | 41.8 | 22.0 | 13.5 | 35.2 |
| w/o gaze encoding | 97.5 | 68.5 | 63.5 | 74.4 |
| w/o knowledge embedding | 97.6 | 69.2 | 68.4 | 70.0 |
Cross-User Generalizability
- The efficacy of PLMs comes from their internal knowledge of identifying tokens in difficult words.
- Over-relying on this factor weaken our method’s performance in cross-user settings.
| Model | Accuracy | F1-score | Precision | Recall |
|---|
| Cross user | 97.3 | 59.6 | 52.8 | 68.4 |
My Contributions
- Proposed this idea, led this project and wrote most of the paper.
- Built a web-based pdf reader using pdf.js and React to collect users’ gaze data while reading.
- Implemented a transformer-based model to detect unknown words based on gaze and text data.
- Showed the robustness of our method on less precise webcam-based gaze data
