
EyeLingo: Unknown Word Detection for English as a Second Language (ESL) Learners Using Gaze and Pre-trained Language Models
English as a Second Language (ESL) learners often encounter unknown words that can hinder their comprehension of text. Automatically detecting these words enables the provision of just-in-time definitions, synonyms, or contextual explanations, facilitating vocabulary acquisition in a natural and seamless manner. This paper presents a transformer-based machine learning model that aligns gaze trajectory with corresponding text and decodes the probability of unknown words within the text in real time with high precision. The user study involving 20 participants revealed that our method can achieve an accuracy of 97.6%, and an F1-score of 71.1%. We also implemented a real-time reading assistance proof-of-concept to show the effectiveness of EnWord. The user study shows improvement in willingness to use and usefulness.
Motivation
- Encountering unknown words can hinder ESL learner’s comprehension of text.
- Eye-tracking devices can be expensive and prone to inaccuracies.
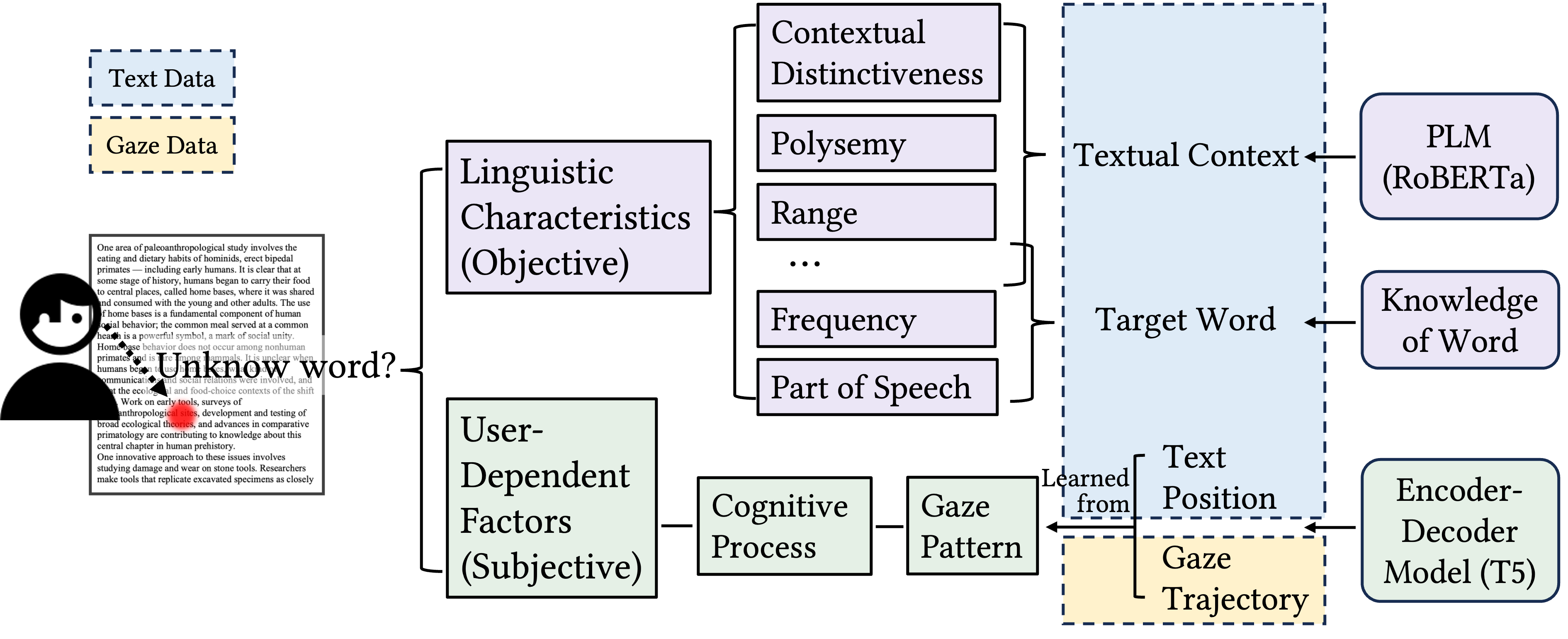
- Besides the cognitive process reflected by gaze, inherent linguistic information about words is also crucial for identifying unknown words.
- We present a real-time unknown word detection method that locates a region of interest based on gaze and then integrates linguistic information provided by PLM and gaze trajectory to predict unknown words using a transformer-based model.
Contributions
- We propose an unknown word detection method (EnWord) that leverages gaze to locate a region of interest and then uses a transformer-based model to make a binary classification based on linguistic characteristics provided by a pre-trained language model and gaze trajectory. It achieves an accuracy of 97.6% and an F1-score of 71.1%.
- We analyzed the contributions of gaze and the pre-trained language model. Unknown word detection is mainly based on linguistic characteristics provided by a pre-trained language model. Gaze provides user-dependent and timely information to detect different unknown words for different user in a real-time manner.
- We built a reading assistance proof-of-concept and conducted a real-time evaluation. The result shows that the F1-score is 56.5%. The user study shows improvement in willingness to use and usefulness.
Method
Software
The model consists of three parts. Linguistic characteristics of the target word’s tokens and the textual context in the region of interest are captured by RoBERTa. Word-level knowledge of the target word such as term frequency, part of speech and named entity recognition are applied to enhance the performance. The gaze pattern is automatically learned from gaze trajectory and text position by the model adapted from T5, one of the top encoder-decoder transformer-based architectures. 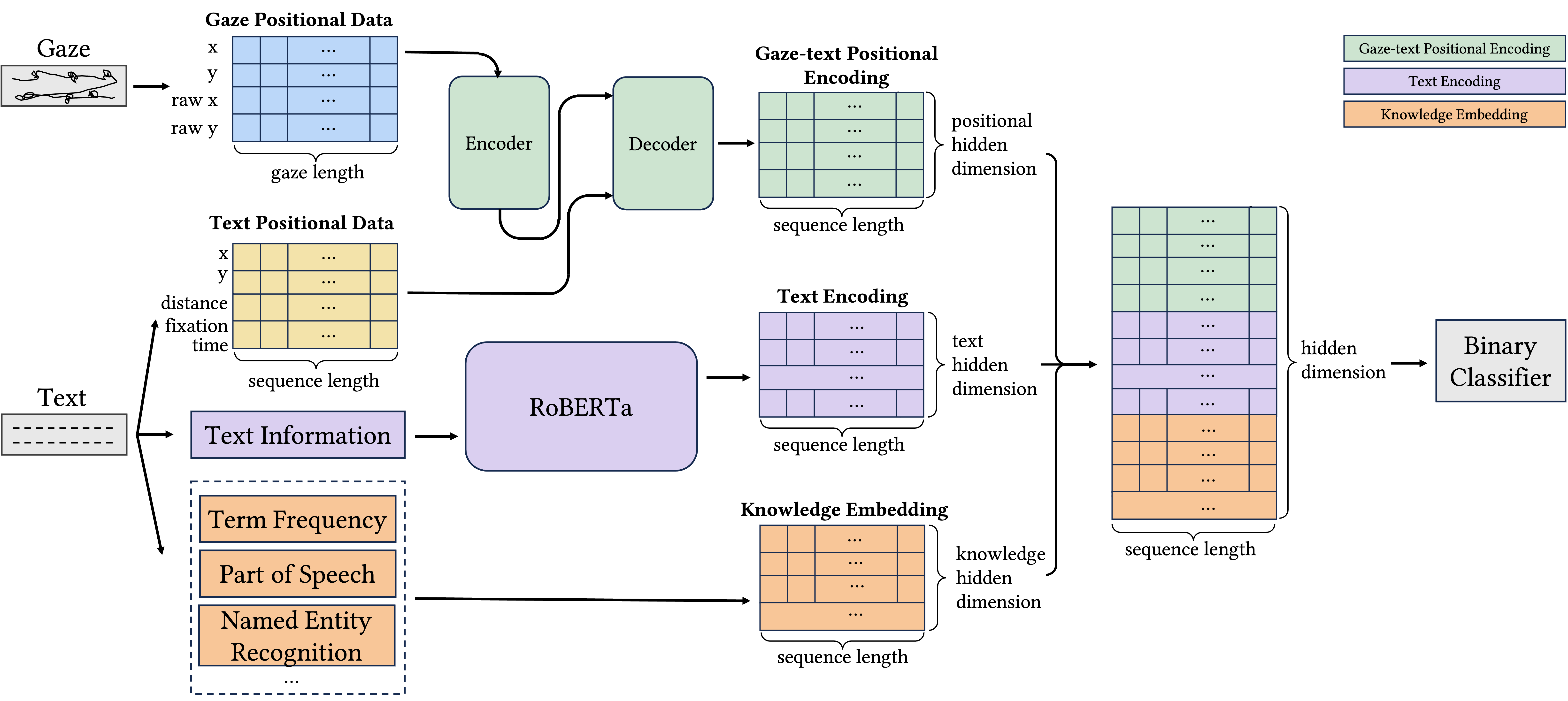
Experiment Results
Main result
Our model achieves impressive results on the data collected using an eye tracker. The accuracy is 97.6% and the F1-score is 71.1%. The average inference latency of the model is 0.036 seconds in the CPU setting, indicating that our method can support real-time applications. To demonstrate the robustness of our method, we applied our method to another dataset collected with a relatively inaccurate webcam-based eye-tracking system. Even when tested with less precise webcam-based data, the model still achieves an accuracy of 97.3% and an F1-score of 65.1%, opening the potential for more accessible solutions than previously possible. 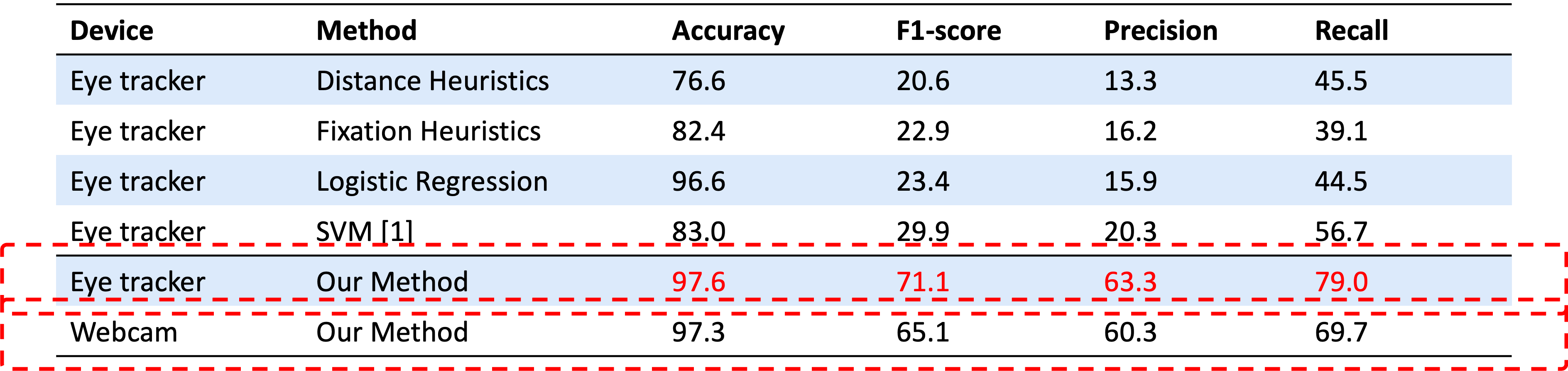
| FaceOri | CAT (SOTA) | |
|---|---|---|
| Yaw | 3.7° | 11.0° |
| Pitch | 5.8° | 11.6° |
| Distance | 10.9 mm | 42.0 mm |
Contribution of Gaze
Then we analyzed the contribution of gaze and PLM. The low Jaccard similarity score indicates that different users have different unknown words even when reading the same document. We cannot identify differences between users only relying on textual information, so it is necessary to use user-dependent gaze features. In the ablation study, the recall drops from 79.0% to 74.4% when removing the gaze. This phenomenon implies that gaze are helpful for identifying an individual’s unknown words based on the user’s unique behaviors and patterns. The result from the case study also shows that gaze provides user-dependent and timely information to detect unknown words for different users. 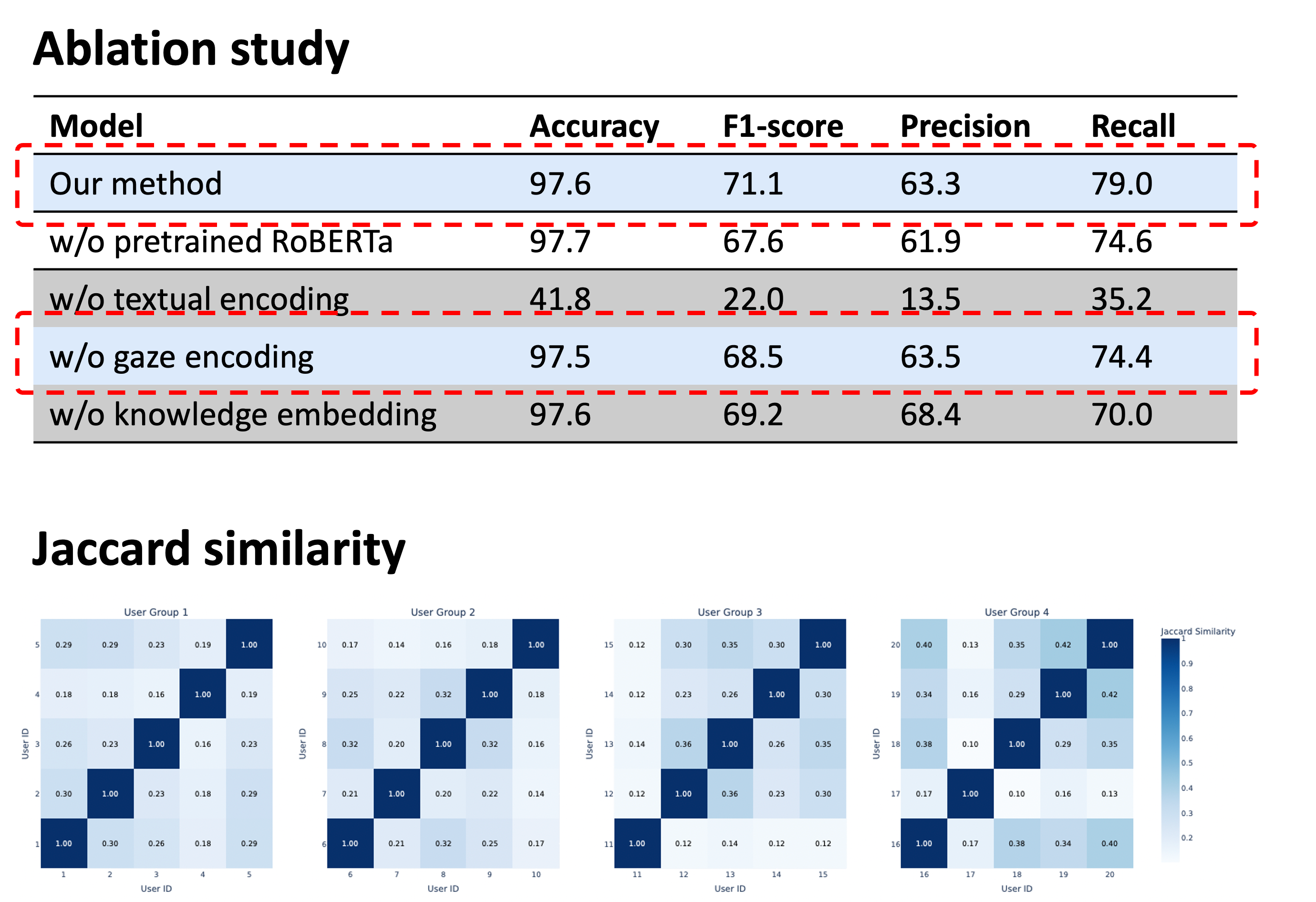
Contribution of PLM
When removing the “pre-trained” weights by randomly initializing RoBERTa weights and removing the whole language model by removing the RoBERTa weights, the F1-score drops to 67.6% and 22.0% respectively. This proves the effectiveness of using PLMs to better capture the contextual information of the documents in the task of unknown word detection. 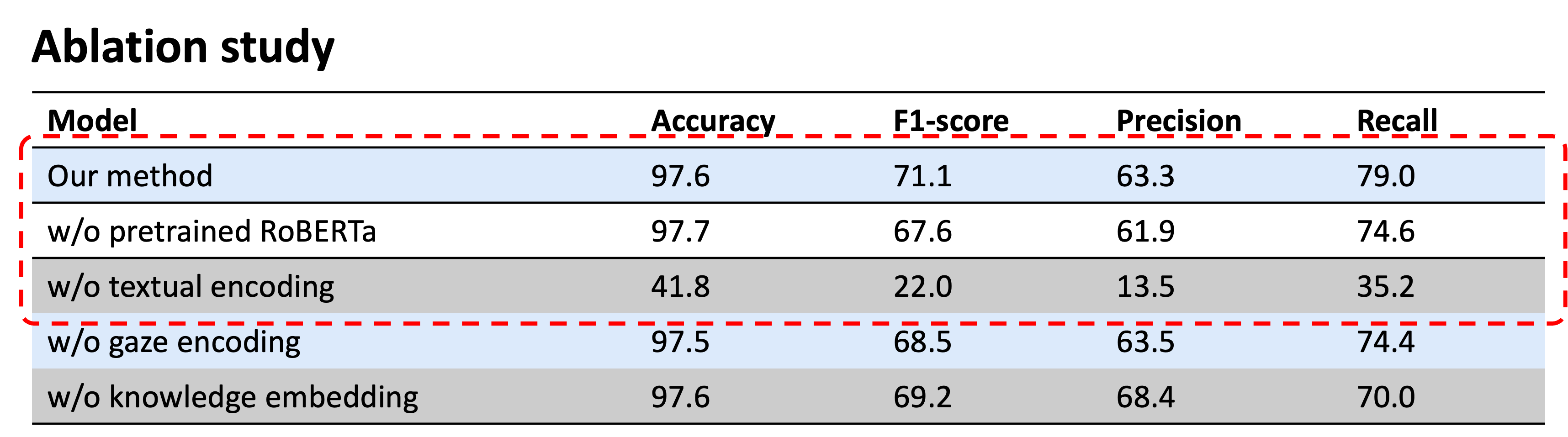
User Evaluation
Furthermore, we built a reading assistance proof-of-concept and conducted a real-time evaluation. The result shows that the F1-score is 56.5%. The user study involved 10 participants shows improvement in reading fluency, willingness to use and usefulness. 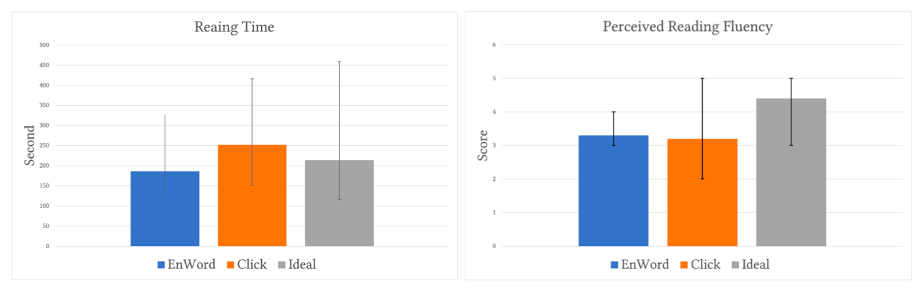
My Contributions
- Developed the transformer model to detect unknown word based on gaze and text.
- Implemented the realtime reading assitant prototype that can generate word explanation and translation in realtime based on the unknown word detected by the model.
- Designed and conducted the user study to test the performance of our system in realtime and get subject feedbacks.